编译原理4——运行存储分配
第七章 运行存储分配
存储组织
- 编译器在工作过程中,必须为程序中出现的一些数据对象分配运行时的存储空间
- 对于那些编译时刻就可以确定大小的数据对象,可以在编译时刻就为之分配——静态存储分配
- 不能在编译时完全确定数据对象的大小——动态存储分配
- 在编译时仅产生各种必要的信息,在运行时刻在动态分配存储空间
- 栈式&堆式
- 在编译时仅产生各种必要的信息,在运行时刻在动态分配存储空间
- 活动记录:
- 使用过程(函数/方法)作为用户自定义动作的单元的语言,其编译器通常以过程为单位分配存储空间
- 过程体每次执行称为该过程的一个活动
- 过程每执行一次,就为它分配一块连续存储区,用来管理过程的一次执行所需的信息,这块连续存储区称为活动记录
静态存储分配
- 编译器为每个过程确定其活动记录在目标程序中的位置
- 确定了每个名字存储位置
- 这些名字的存储地址可以被编译到目标代码中
过程每次执行时,它的名字都绑定到同样的存储单元
适合语言条件
- 数组上下界必须是常数
- 不允许递归的过程调用
- 不允许动态建立数据实体
- 常用静态存储分配方法
- 顺序分配法
- 按照过程分配的先后顺序逐段分配存储空间
- 各过程的活动记录占用互不相交的存储空间
- 优点:处理简单
- 缺点:不够经济合理
- 层次分配法
- 通过对过程间的调用关系进行分析,凡属于无相互调用关系的并列过程,尽量使用其局部数据共享存储单元。
- B[n][n]:过程调用关系矩阵
- B[i][j]:1——第i个过程调用第j个过程;0——不调用
- Units[n]:过程所需内存量矩阵
- base[i]:第i个过程局部数据区的基地址
- allocate[i]:第i个过程局部数据区是否分配的标志
- 顺序分配法
栈式存储分配
有些语言使用过程、函数或方法作为用户自定义动作的单元,几乎所有针对这些语言的编译器都把它们的运行时刻存储以栈的形式进行管理。
当一个过程被调用时,该过程的活动记录被压入栈;当过程结束时,该活动记录被弹出栈。
这种安排不仅允许活跃时段不交叠的的多个过程调用之间共享空间,而且允许以如下过程编译代码:
- 非局部变量的相对地址总是固定的,和过程调用序列无关
活动树
用来描述程序运行期间控制进入和离开的各个活动的情况的树
在表示过程p的某个活动的结点上,其子结点对应于被p的这次活动调用的各个过程的活动。按照这些活动被调用的顺序,自左向右的显示它们。一个子结点必须在其右兄弟结点的活动开始之前结束。
- 每个活跃的活动都有一个位于控制栈中的活动记录
- 活动树的根的活动记录位于栈底
- 程序控制所在的活动记录位于栈顶
- 栈中全部活动记录的序列对应于在活动树中到达当前控制所在的活动结点的路径。
设计活动树的一些原则
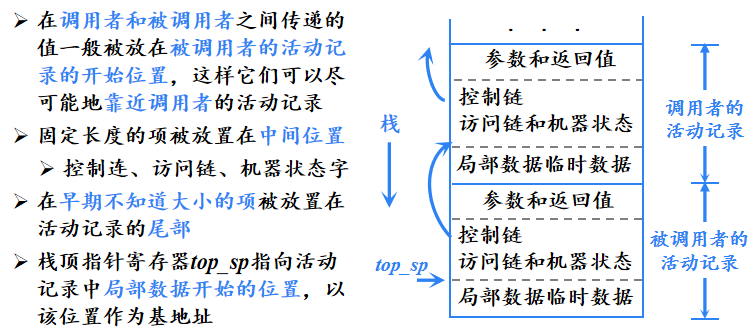
调用序列和返回序列
过程调用和过程返回都需要执行一些代码来管理活动记录站,保存或恢复机器状态等
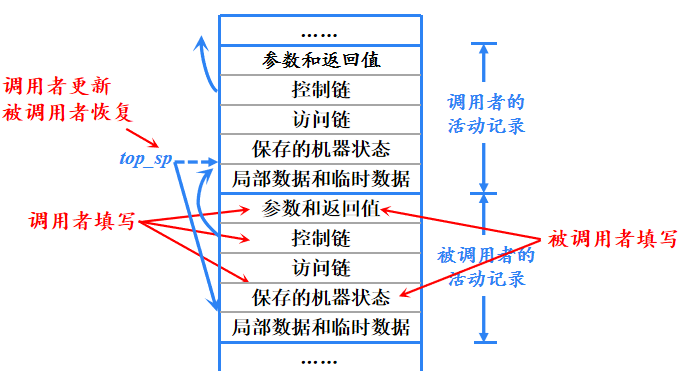
- 调用序列:实现过程调用的代码段,为一个活动记录在栈中分配空间,并在此记录的字段中填写信息。
- 返回序列:恢复机器状态,使得调用过程能够在被调用结束后继续执行。
- 一个调用代码序列中的代码通常被分割到调用过程和被调用过程中;返回序列同理。
调用序列

返回序列

调用者和被调用者之间的任务划分
变长数据的存储分配
- 在现代程序设计语言中,在编译时刻不能确定大小的对象被分配到堆区;但是过程的局部对象也可以分配在运行时刻栈中。
- 尽量将对象放置在栈区原因:避免垃圾回收,减小开销
- 只有一个数据对象局部于某个过程,且当此过程结束时它变得不可访问,才可以使用栈为这个对象分配空间。
- 在现代程序设计语言中,在编译时刻不能确定大小的对象被分配到堆区;但是过程的局部对象也可以分配在运行时刻栈中。
非局部数据的访问
- 一个过程除了可以使用过程自身定义的局部数据以外,还可以使用过程外定义的非局部数据
- 语言可以分为两种类型
- 支持过程嵌套声明的的语言
- 可以在一个过程中声明另一个过程(eg:Pascal)
- 不支持过程嵌套声明的语言
- eg:C
- 支持过程嵌套声明的的语言
无过程嵌套声明时的数据访问
- 变量的存储分配和访问
- 全局变量被分配在静态区使用静态确定的地址访问它们
- 其他变量一定是栈顶活动的局部变量,可以通过运行时栈的top_sp指针访问它们
- 变量的存储分配和访问
有过程嵌套声明时的数据访问
- 嵌套深度
- 过程的嵌套深度
- 不内嵌在任何其他过程中的过程,其嵌套深度为1
- 在嵌套深度为i的过程中定义的过程的嵌套深度为i+1
- 变量的嵌套深度
- 将变量声明所在过程的嵌套深度作为该变量得分嵌套深度
- 过程的嵌套深度
- 嵌套深度
访问链
- 静态作用域规则:只要过程b的声明嵌套在a的声明中,过程b就可以访问过程a中声明的对象
- 在相互嵌套的过程活动记录之间建立访问链(指针),使得内嵌的过程可以访问外层过程中声明的对象
- 如果b在源代码中直接嵌套于a($n_b=n_a+1,n为嵌套深度$),那么b的任何活动中的访问链指针都指向最近的a的活动
访问链的建立
- 建立访问链的代码属于调用序列的一部分
- 过程x调用过程y:
- $n_x<n_y$:y一定由x直接定义,$n_y=n_x+1$
- 在y的访问链中放置一个指向x的活动记录的指针
- $n_x=n_y$:本层调用本层(eg:递归)
- 直接复制上层的访问链
- $n_x>n_y$:调用者x嵌套于某过程z,而z中直接定义了被调用者y
- y的访问链指向z的距离栈顶最近的活动记录($n_x-n_y+1$步)
- $n_x<n_y$:y一定由x直接定义,$n_y=n_x+1$
符号表
- 符号表的组织
- 为每个作用域(程序块)建立一个独立的符号表
- 这种为每个过程或作用域建立的符号表与编译时的活动记录是对应的。一个过程的非局部名字的信息可以通过扫描外围过程的符号表得到。
标识符的基本处理方法
- 当某一层的声明语句中识别出一个标识符(定义出现)时,以此标识符查询本层的符号表
- 查到——id重复声明
- 没查到——进行登记,将相关信息填入符号表
- 在可执行语句中发现标识符(应用出现)
- 在该层符号表中查找,找不到则到直接外层找,逐步向外查找,一旦找到则取出相关信息并处理
- 所有外层都找不到——id未声明
- 当某一层的声明语句中识别出一个标识符(定义出现)时,以此标识符查询本层的符号表
符号表的建立
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!